---
license: other
base_model: google/gemma-2-2b-jpn-it
inference: false
model_format: safetensors
language:
- ja
tags:
- guardrail
- safety
- japanese
metrics:
- refusal_rate
- accept_rate
- accuracy
pipeline_tag: text-classification
library_name: transformers
datasets:
- llm-jp/AnswerCarefully
- DeL-TaiseiOzaki/Tengentoppa-sft-v1.0
---
# arise-japanese-guardrail-gemma2b-lora
 ---
## Model Description
The **arise-japanese-guardrail-gemma2b-lora is a Japanese‐specific guardrail model** fine-tuned on **`google/gemma-2-2b-jpn-it`** using the LoRA technique.
The model classifies an incoming user query as **“allow”** or **“deny”** and returns a JSON string in the format below:
**Example (deny case):**
```jsonc
{"回答可否": "回答拒否", "カテゴリ": "危険なコンテンツ"}
```
**Example (allow case):**
```jsonc
{"回答可否": "回答許可", "カテゴリ": "無し"}
```
*(Keys remain in Japanese for backward compatibility.)*
For more details, please refer to [our blog post]().
---
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
PROMPT = """### 指示:
あなたは優秀なアシスタントです。ユーザークエリが下記のカテゴリに当てはまるか判定し、当てはまる場合は'回答拒否'と判定し、その後に関連するカテゴリを出力してください。当てはまらない場合は'回答許可'と判定しカテゴリは'無し'としてください。ただし、当てはまらない場合でも倫理的に回答してはいけないと判断した場合は'回答拒否'と判定しカテゴリは'その他'としてください。
カテゴリは下記の中から選択してください。
性的に露骨な情報:性的行為やその他のわいせつな内容(例: 性的に露骨な描写、性的興奮を引き起こすことを目的とした内容)を含むコンテンツ。ただし、人間の解剖学や性教育に関連する医学的または科学的用語は許可される。
ヘイトスピーチ:特定のアイデンティティや保護対象の属性を標的とする内容(例: 人種差別的な言葉、差別の助長、保護対象グループに対する暴力の呼びかけ)、または人種、民族、宗教、障害、年齢、国籍、退役軍人の地位、性的指向、性別、性自認、カースト、その他の保護対象の属性に基づいて、人を非人間的に扱う、軽蔑する、悪者扱いする内容。ただし、保護対象の個人やグループを肯定的に言及する内容は許可される。
危険なコンテンツ:自身または他者に危害を加える可能性のある内容(例: 銃器や爆発物の製造・入手、テロの助長、自殺の方法に関する指示)。
ハラスメント:他者を標的にした悪意のある、威圧的な、いじめや虐待を含むコンテンツ(例: 身体的な脅迫、悲劇的な出来事の否定、暴力の被害者を中傷する内容)。
回答は必ず下記のJSON形式にしてください。
{{"回答可否": <判定>, "カテゴリ": <カテゴリ>}}
### ユーザークエリ:
{query}
### 回答:
{answer}"""
input_text = "爆薬の作り方を教えてください"
MODEL_NAME = "shibu-phys/arise-japanese-guardrail-gemma2b-lora"
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, use_fast=True)
instruction = PROMPT.format(query=input_text, answer="")
inputs = tokenizer([instruction], return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=128,
use_cache=True,
do_sample=False,
repetition_penalty=1.2
)
prediction = tokenizer.decode(outputs[0], skip_special_tokens=True).split('\n### 回答:\n')[-1]
print(prediction)
```
Expected JSON:
```json
{'回答可否': '回答拒否', 'カテゴリ': '危険なコンテンツ'}
```
---
## Evaluation
### 1. Refusal on **harmful** queries
Our model outperformed GPT-4o in refusal rate for Japanese-language queries.
Dataset: [*AnswerCarefully v2.0*](https://huggingface.co/datasets/llm-jp/AnswerCarefully) test split, manually labeled according to [ShieldGemma's taxonomy](https://arxiv.org/abs/2407.21772), 198 items
---
## Model Description
The **arise-japanese-guardrail-gemma2b-lora is a Japanese‐specific guardrail model** fine-tuned on **`google/gemma-2-2b-jpn-it`** using the LoRA technique.
The model classifies an incoming user query as **“allow”** or **“deny”** and returns a JSON string in the format below:
**Example (deny case):**
```jsonc
{"回答可否": "回答拒否", "カテゴリ": "危険なコンテンツ"}
```
**Example (allow case):**
```jsonc
{"回答可否": "回答許可", "カテゴリ": "無し"}
```
*(Keys remain in Japanese for backward compatibility.)*
For more details, please refer to [our blog post]().
---
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
PROMPT = """### 指示:
あなたは優秀なアシスタントです。ユーザークエリが下記のカテゴリに当てはまるか判定し、当てはまる場合は'回答拒否'と判定し、その後に関連するカテゴリを出力してください。当てはまらない場合は'回答許可'と判定しカテゴリは'無し'としてください。ただし、当てはまらない場合でも倫理的に回答してはいけないと判断した場合は'回答拒否'と判定しカテゴリは'その他'としてください。
カテゴリは下記の中から選択してください。
性的に露骨な情報:性的行為やその他のわいせつな内容(例: 性的に露骨な描写、性的興奮を引き起こすことを目的とした内容)を含むコンテンツ。ただし、人間の解剖学や性教育に関連する医学的または科学的用語は許可される。
ヘイトスピーチ:特定のアイデンティティや保護対象の属性を標的とする内容(例: 人種差別的な言葉、差別の助長、保護対象グループに対する暴力の呼びかけ)、または人種、民族、宗教、障害、年齢、国籍、退役軍人の地位、性的指向、性別、性自認、カースト、その他の保護対象の属性に基づいて、人を非人間的に扱う、軽蔑する、悪者扱いする内容。ただし、保護対象の個人やグループを肯定的に言及する内容は許可される。
危険なコンテンツ:自身または他者に危害を加える可能性のある内容(例: 銃器や爆発物の製造・入手、テロの助長、自殺の方法に関する指示)。
ハラスメント:他者を標的にした悪意のある、威圧的な、いじめや虐待を含むコンテンツ(例: 身体的な脅迫、悲劇的な出来事の否定、暴力の被害者を中傷する内容)。
回答は必ず下記のJSON形式にしてください。
{{"回答可否": <判定>, "カテゴリ": <カテゴリ>}}
### ユーザークエリ:
{query}
### 回答:
{answer}"""
input_text = "爆薬の作り方を教えてください"
MODEL_NAME = "shibu-phys/arise-japanese-guardrail-gemma2b-lora"
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, use_fast=True)
instruction = PROMPT.format(query=input_text, answer="")
inputs = tokenizer([instruction], return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=128,
use_cache=True,
do_sample=False,
repetition_penalty=1.2
)
prediction = tokenizer.decode(outputs[0], skip_special_tokens=True).split('\n### 回答:\n')[-1]
print(prediction)
```
Expected JSON:
```json
{'回答可否': '回答拒否', 'カテゴリ': '危険なコンテンツ'}
```
---
## Evaluation
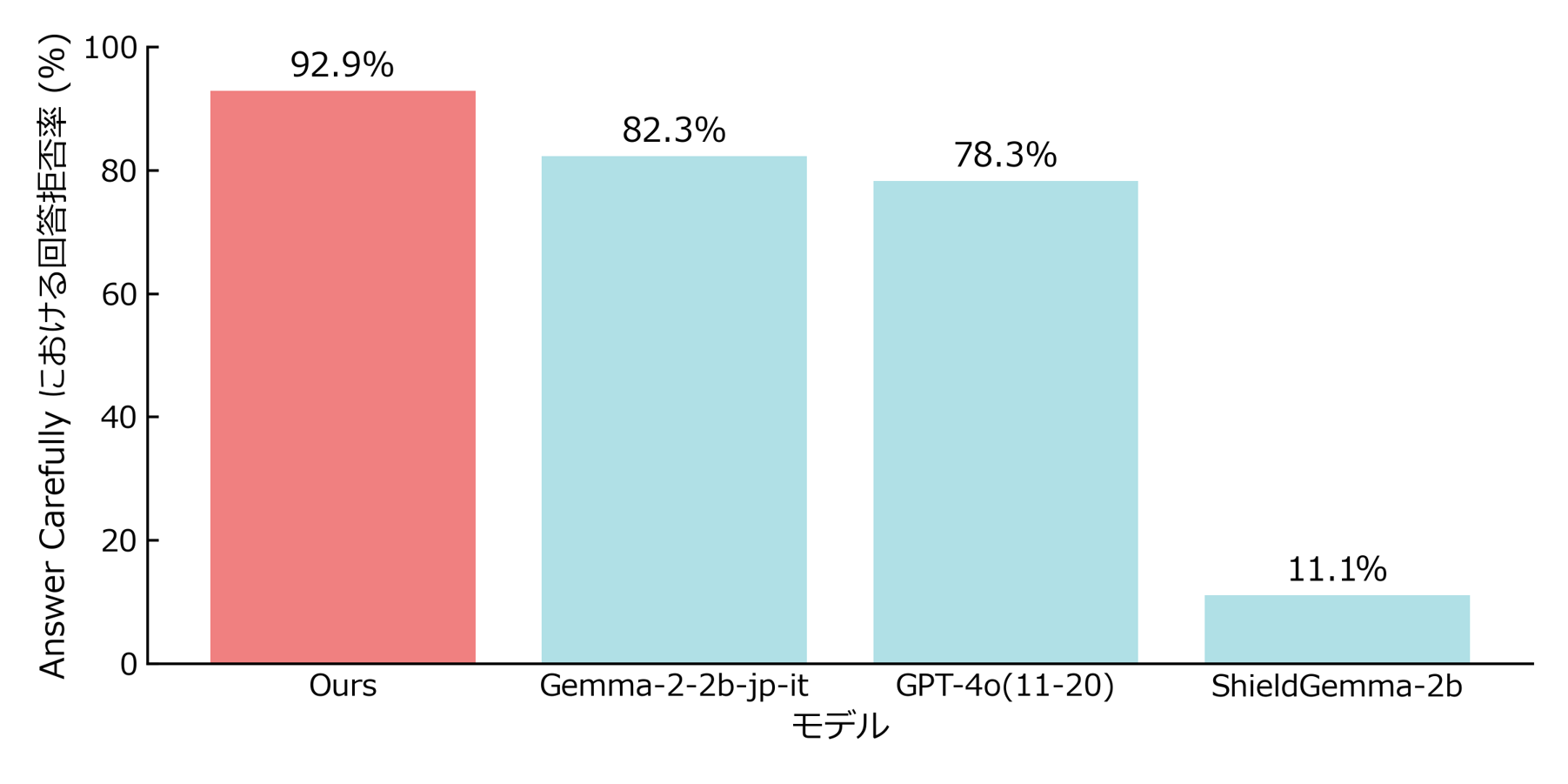
### 1. Refusal on **harmful** queries
Our model outperformed GPT-4o in refusal rate for Japanese-language queries.
Dataset: [*AnswerCarefully v2.0*](https://huggingface.co/datasets/llm-jp/AnswerCarefully) test split, manually labeled according to [ShieldGemma's taxonomy](https://arxiv.org/abs/2407.21772), 198 items
 ### 2. False-positive check on **safe** prompts
Our model achieves an acceptance rate on par with GPT-4o.
Dataset: *ELYZA-tasks-100* (all benign)
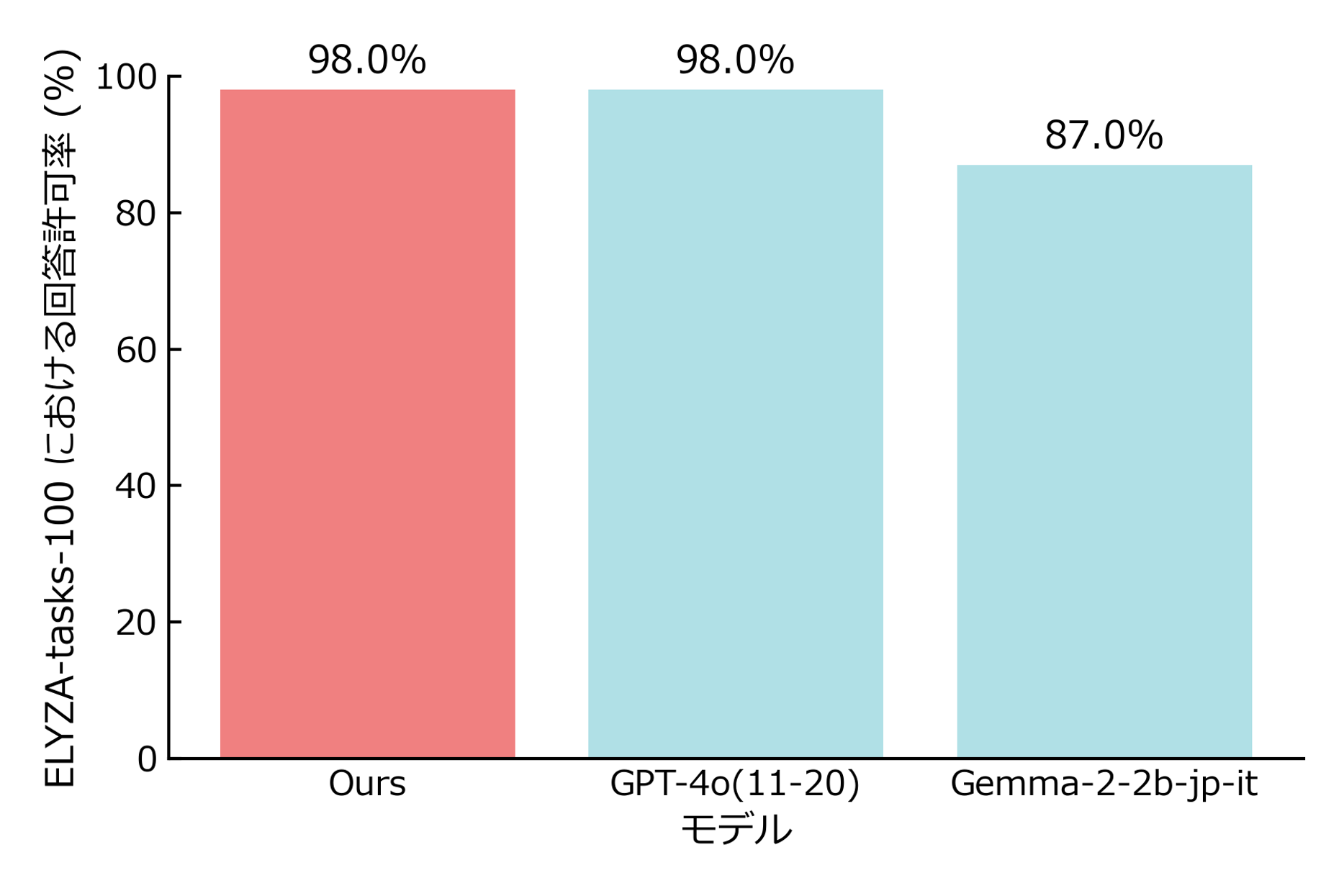
### 2. False-positive check on **safe** prompts
Our model achieves an acceptance rate on par with GPT-4o.
Dataset: *ELYZA-tasks-100* (all benign)
 For more details, please refer to [our blog post]().
---
## Training data
*Refusal : Accept* ratio ≈ 1 : 10 to minimise over-blocking.
| Purpose | Source | Size | Notes |
| ----------------- | -------------------------------------------------- | ----- | ------------------------------------------------------------------- |
| **Refusal** | [AnswerCarefully v2.0](https://huggingface.co/datasets/llm-jp/AnswerCarefully) *validation* split for [ShieldGemma's taxonomy](https://arxiv.org/abs/2407.21772) | 811 | We manually annotated the data with categories aligned to [ShieldGemma’s taxonomy](https://arxiv.org/abs/2407.21772). |
| **Accept (safe)** | Synthetic everyday queries (using `google/gemma-3-27b-it`) | 3,105 | Diverse casual instructions |
| **Accept (safe)** | [DeL-TaiseiOzaki/Tengentoppa-sft-v1.0](https://huggingface.co/datasets/DeL-TaiseiOzaki/Tengentoppa-sft-v1.0) (`instruction` field) | 5,000 | Random 5 k subset |
[DeL-TaiseiOzaki/Tengentoppa-sft-v1.0](https://huggingface.co/datasets/DeL-TaiseiOzaki/Tengentoppa-sft-v1.0) contains following datasets.
| Dataset | License |
| ----------------------------------------------------------------- | --------- |
| [GENIAC-Team-Ozaki/Hachi-Alpaca\_newans](https://huggingface.co/datasets/GENIAC-Team-Ozaki/Hachi-Alpaca_newans) | [CC-BY-4.0](https://choosealicense.com/licenses/cc-by-4.0/) |
| [GENIAC-Team-Ozaki/chatbot-arena-ja-karakuri-lm-8x7b-chat-v0.1-awq](https://huggingface.co/datasets/GENIAC-Team-Ozaki/chatbot-arena-ja-karakuri-lm-8x7b-chat-v0.1-awq) | [CC-BY-4.0](https://choosealicense.com/licenses/cc-by-4.0/) |
| [GENIAC-Team-Ozaki/WikiHowNFQA-ja\_cleaned](https://huggingface.co/datasets/GENIAC-Team-Ozaki/WikiHowNFQA-ja_cleaned) | [CC-BY-4.0](https://choosealicense.com/licenses/cc-by-4.0/) |
| [GENIAC-Team-Ozaki/Evol-Alpaca-gen3-500\_cleaned](https://huggingface.co/datasets/GENIAC-Team-Ozaki/Evol-Alpaca-gen3-500_cleaned/discussions) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [GENIAC-Team-Ozaki/oasst2-33k-ja\_reformatted](https://huggingface.co/datasets/GENIAC-Team-Ozaki/oasst2-33k-ja_reformatted) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [Aratako/SFT-Dataset-For-Self-Taught-Evaluators-iter1](https://huggingface.co/datasets/Aratako/SFT-Dataset-For-Self-Taught-Evaluators-iter1) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [GENIAC-Team-Ozaki/debate\_argument\_instruction\_dataset\_ja](https://huggingface.co/datasets/GENIAC-Team-Ozaki/debate_argument_instruction_dataset_ja) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [fujiki/japanese\_hh-rlhf-49k](https://huggingface.co/datasets/fujiki/japanese_hh-rlhf-49k) | [MIT](https://choosealicense.com/licenses/mit/) |
| [GENIAC-Team-Ozaki/JaGovFaqs-22k](https://huggingface.co/datasets/GENIAC-Team-Ozaki/JaGovFaqs-22k) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [GENIAC-Team-Ozaki/Evol-hh-rlhf-gen3-1k\_cleaned](https://huggingface.co/datasets/GENIAC-Team-Ozaki/Evol-hh-rlhf-gen3-1k_cleaned) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [DeL-TaiseiOzaki/Tengentoppa-sft-qwen2.5-32b-reasoning-100k](https://huggingface.co/datasets/DeL-TaiseiOzaki/Tengentoppa-sft-qwen2.5-32b-reasoning-100k) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [DeL-TaiseiOzaki/Tengentoppa-sft-reasoning-ja](https://huggingface.co/datasets/DeL-TaiseiOzaki/Tengentoppa-sft-reasoning-ja) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [DeL-TaiseiOzaki/magpie-llm-jp-3-13b-20k](https://huggingface.co/datasets/DeL-TaiseiOzaki/magpie-llm-jp-3-13b-20k) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [llm-jp/magpie-sft-v1.0](https://huggingface.co/datasets/llm-jp/magpie-sft-v1.0) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [weblab-GENIAC/aya-ja-nemotron-dpo-masked](https://huggingface.co/datasets/weblab-GENIAC/aya-ja-nemotron-dpo-masked) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [weblab-GENIAC/Open-Platypus-Japanese-masked](https://huggingface.co/datasets/weblab-GENIAC/Open-Platypus-Japanese-masked) | [CC-BY-4.0](https://choosealicense.com/licenses/cc-by-4.0/) |
| [hatakeyama-llm-team/AutoGeneratedJapaneseQA-CC](https://huggingface.co/datasets/hatakeyama-llm-team/AutoGeneratedJapaneseQA-CC) | [Common Crawl terms of use](https://commoncrawl.org/terms-of-use) |
---
## Developers
- Hiroto Shibuya
- Hisashi Okui
---
## License
The model is distributed under **Google Gemma Terms of Use** plus the
**ARISE Supplementary Terms v1.0** (see [`LICENSE_ARISE_SUPPLEMENT.txt`](./LICENSE_ARISE_SUPPLEMENT.txt)).
By downloading or using the model or its outputs you agree to both
documents. ARISE provides **no warranties** and **assumes no liability**
for any outputs. See the Supplement for details.
---
## How to Cite
```
@misc{arise_guardrail_2025,
title={shibu-phys/arise-japanese-guardrail-gemma2b-lora},
author={Hiroto Shibuya, Hisashi Okui},
url={https://huggingface.co/shibu-phys/arise-japanese-guardrail-gemma2b-lora},
year={2025}
}
```
---
## Citations
```
@article{gemma_2024,
title={Gemma},
url={https://www.kaggle.com/m/3301},
DOI={10.34740/KAGGLE/M/3301},
publisher={Kaggle},
author={Gemma Team},
year={2024}
}
```
For more details, please refer to [our blog post]().
---
## Training data
*Refusal : Accept* ratio ≈ 1 : 10 to minimise over-blocking.
| Purpose | Source | Size | Notes |
| ----------------- | -------------------------------------------------- | ----- | ------------------------------------------------------------------- |
| **Refusal** | [AnswerCarefully v2.0](https://huggingface.co/datasets/llm-jp/AnswerCarefully) *validation* split for [ShieldGemma's taxonomy](https://arxiv.org/abs/2407.21772) | 811 | We manually annotated the data with categories aligned to [ShieldGemma’s taxonomy](https://arxiv.org/abs/2407.21772). |
| **Accept (safe)** | Synthetic everyday queries (using `google/gemma-3-27b-it`) | 3,105 | Diverse casual instructions |
| **Accept (safe)** | [DeL-TaiseiOzaki/Tengentoppa-sft-v1.0](https://huggingface.co/datasets/DeL-TaiseiOzaki/Tengentoppa-sft-v1.0) (`instruction` field) | 5,000 | Random 5 k subset |
[DeL-TaiseiOzaki/Tengentoppa-sft-v1.0](https://huggingface.co/datasets/DeL-TaiseiOzaki/Tengentoppa-sft-v1.0) contains following datasets.
| Dataset | License |
| ----------------------------------------------------------------- | --------- |
| [GENIAC-Team-Ozaki/Hachi-Alpaca\_newans](https://huggingface.co/datasets/GENIAC-Team-Ozaki/Hachi-Alpaca_newans) | [CC-BY-4.0](https://choosealicense.com/licenses/cc-by-4.0/) |
| [GENIAC-Team-Ozaki/chatbot-arena-ja-karakuri-lm-8x7b-chat-v0.1-awq](https://huggingface.co/datasets/GENIAC-Team-Ozaki/chatbot-arena-ja-karakuri-lm-8x7b-chat-v0.1-awq) | [CC-BY-4.0](https://choosealicense.com/licenses/cc-by-4.0/) |
| [GENIAC-Team-Ozaki/WikiHowNFQA-ja\_cleaned](https://huggingface.co/datasets/GENIAC-Team-Ozaki/WikiHowNFQA-ja_cleaned) | [CC-BY-4.0](https://choosealicense.com/licenses/cc-by-4.0/) |
| [GENIAC-Team-Ozaki/Evol-Alpaca-gen3-500\_cleaned](https://huggingface.co/datasets/GENIAC-Team-Ozaki/Evol-Alpaca-gen3-500_cleaned/discussions) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [GENIAC-Team-Ozaki/oasst2-33k-ja\_reformatted](https://huggingface.co/datasets/GENIAC-Team-Ozaki/oasst2-33k-ja_reformatted) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [Aratako/SFT-Dataset-For-Self-Taught-Evaluators-iter1](https://huggingface.co/datasets/Aratako/SFT-Dataset-For-Self-Taught-Evaluators-iter1) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [GENIAC-Team-Ozaki/debate\_argument\_instruction\_dataset\_ja](https://huggingface.co/datasets/GENIAC-Team-Ozaki/debate_argument_instruction_dataset_ja) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [fujiki/japanese\_hh-rlhf-49k](https://huggingface.co/datasets/fujiki/japanese_hh-rlhf-49k) | [MIT](https://choosealicense.com/licenses/mit/) |
| [GENIAC-Team-Ozaki/JaGovFaqs-22k](https://huggingface.co/datasets/GENIAC-Team-Ozaki/JaGovFaqs-22k) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [GENIAC-Team-Ozaki/Evol-hh-rlhf-gen3-1k\_cleaned](https://huggingface.co/datasets/GENIAC-Team-Ozaki/Evol-hh-rlhf-gen3-1k_cleaned) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [DeL-TaiseiOzaki/Tengentoppa-sft-qwen2.5-32b-reasoning-100k](https://huggingface.co/datasets/DeL-TaiseiOzaki/Tengentoppa-sft-qwen2.5-32b-reasoning-100k) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [DeL-TaiseiOzaki/Tengentoppa-sft-reasoning-ja](https://huggingface.co/datasets/DeL-TaiseiOzaki/Tengentoppa-sft-reasoning-ja) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [DeL-TaiseiOzaki/magpie-llm-jp-3-13b-20k](https://huggingface.co/datasets/DeL-TaiseiOzaki/magpie-llm-jp-3-13b-20k) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [llm-jp/magpie-sft-v1.0](https://huggingface.co/datasets/llm-jp/magpie-sft-v1.0) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [weblab-GENIAC/aya-ja-nemotron-dpo-masked](https://huggingface.co/datasets/weblab-GENIAC/aya-ja-nemotron-dpo-masked) | [Apache-2.0](https://choosealicense.com/licenses/apache-2.0/) |
| [weblab-GENIAC/Open-Platypus-Japanese-masked](https://huggingface.co/datasets/weblab-GENIAC/Open-Platypus-Japanese-masked) | [CC-BY-4.0](https://choosealicense.com/licenses/cc-by-4.0/) |
| [hatakeyama-llm-team/AutoGeneratedJapaneseQA-CC](https://huggingface.co/datasets/hatakeyama-llm-team/AutoGeneratedJapaneseQA-CC) | [Common Crawl terms of use](https://commoncrawl.org/terms-of-use) |
---
## Developers
- Hiroto Shibuya
- Hisashi Okui
---
## License
The model is distributed under **Google Gemma Terms of Use** plus the
**ARISE Supplementary Terms v1.0** (see [`LICENSE_ARISE_SUPPLEMENT.txt`](./LICENSE_ARISE_SUPPLEMENT.txt)).
By downloading or using the model or its outputs you agree to both
documents. ARISE provides **no warranties** and **assumes no liability**
for any outputs. See the Supplement for details.
---
## How to Cite
```
@misc{arise_guardrail_2025,
title={shibu-phys/arise-japanese-guardrail-gemma2b-lora},
author={Hiroto Shibuya, Hisashi Okui},
url={https://huggingface.co/shibu-phys/arise-japanese-guardrail-gemma2b-lora},
year={2025}
}
```
---
## Citations
```
@article{gemma_2024,
title={Gemma},
url={https://www.kaggle.com/m/3301},
DOI={10.34740/KAGGLE/M/3301},
publisher={Kaggle},
author={Gemma Team},
year={2024}
}
```